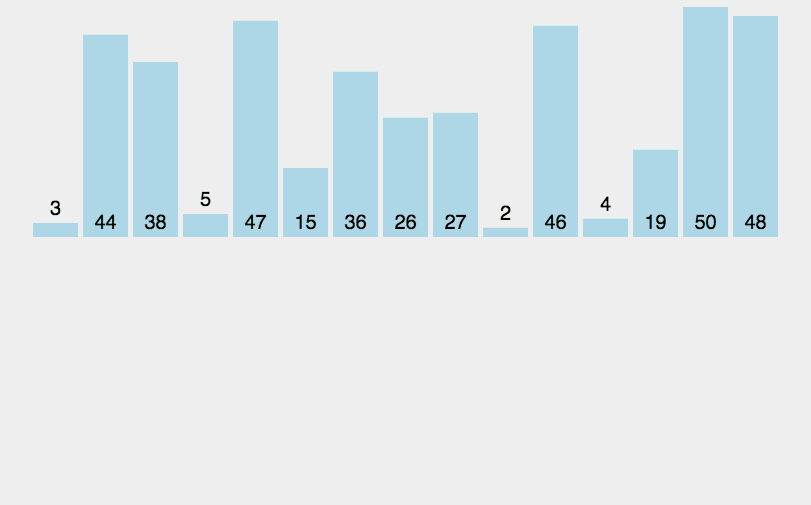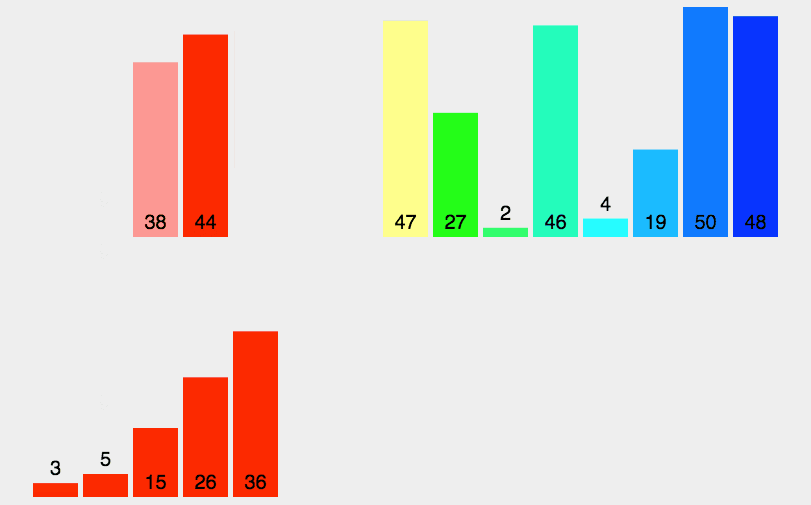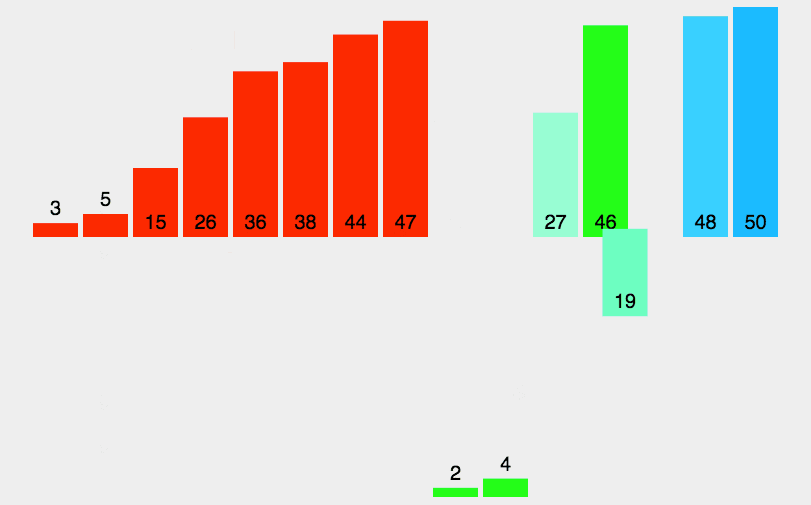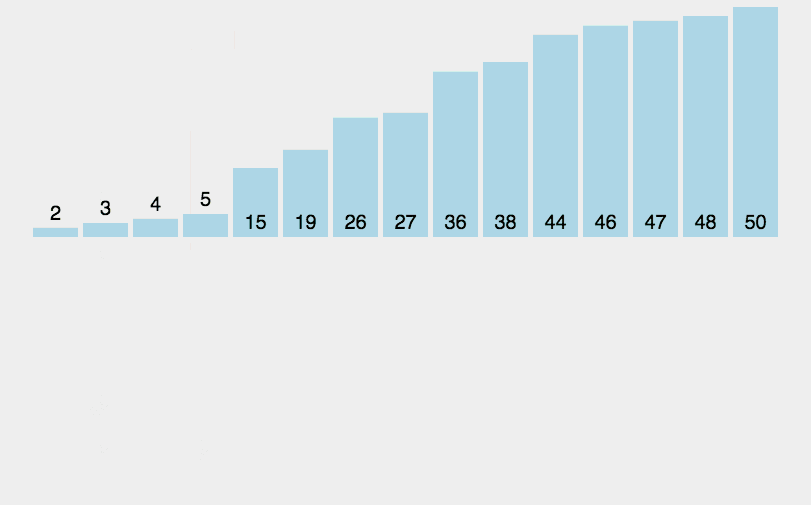
时间复杂度为o(nlogn)的算法
1.归并排序
算法描述
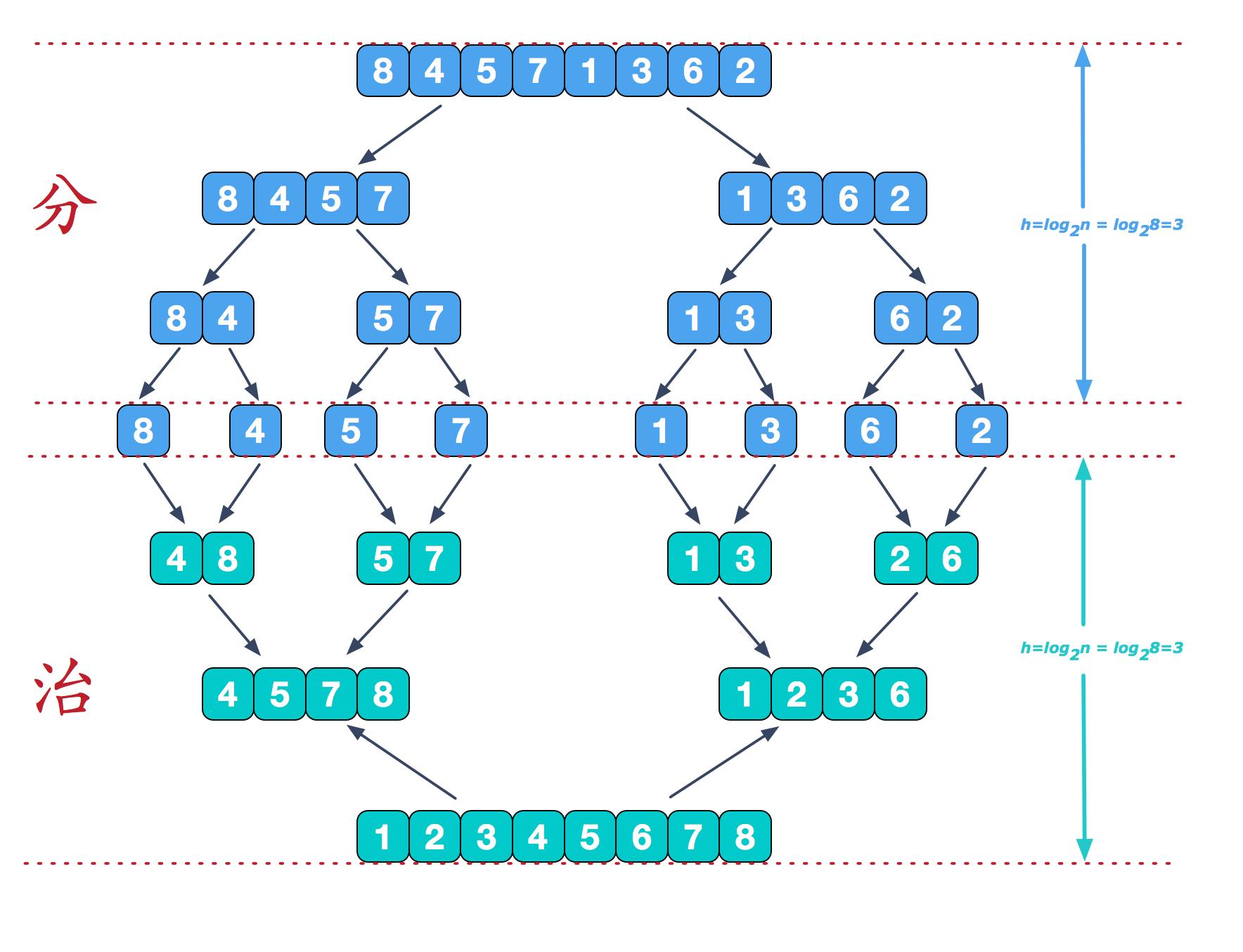
归并排序,是创建在归并操作上的一种有效的排序算法。算法是采用分治法(Divide and Conquer)的一个非常典型的应用,且各层分治递归可以同时进行。归并排序思路简单,速度仅次于快速排序,为稳定排序算法,一般用于对总体无序,但是各子项相对有序的数列。
归并排序是用分治思想,分治模式在每一层递归上有三个步骤:
- 分解(Divide):将n个元素分成个含n/2个元素的子序列。
- 解决(Conquer):用合并排序法对两个子序列递归的排序。
- 合并(Combine):合并两个已排序的子序列已得到排序结果。
简单来说,归并排序的核心思想就是将数组的元素不断的拆分成最小项,然后再不断的比较合并,最终整合成一个整体有序的数组。
动图演示
(点击查看)
代码示例
本实例中使用的是递归法。
private static int[] arr;//使用时记得初始化数组
public static void mergeSort(int[] nums,int lo,int hi){
if (hi<=lo){
return;
}
int mid=lo+(hi-lo)/2;
//左子组拆分
mergeSort(nums,lo,mid);
//右子组拆分
mergeSort(nums,mid+1,hi);
//合并
merge(nums,lo,mid,hi);
}
public static void merge(int[] nums,int lo,int mid,int hi){
int i=lo;
int left=lo;
int right=mid+1;
while (left<=mid&&right<=hi){
if (nums[left]<nums[right]){
arr[i++]=nums[left++];
}else {
arr[i++]=nums[right++];
}
}
while (left<=mid){
arr[i++]=nums[left++];
}
while (right<=hi){
arr[i++]=nums[right++];
}
//将辅助数组复制到原数组
for (int j = lo; j <=hi ; j++) {
nums[j]=arr[j];
}
}
通过代码我们可以看到,归并排序需要借助一个辅助的数组帮助我们去合并有序的数组,因此额外的空间复杂度为O(n)。因为我们在遇到相等的数据的时候必然是按顺序“抄写”到辅助数组上的,所以,归并排序同样是稳定算法。
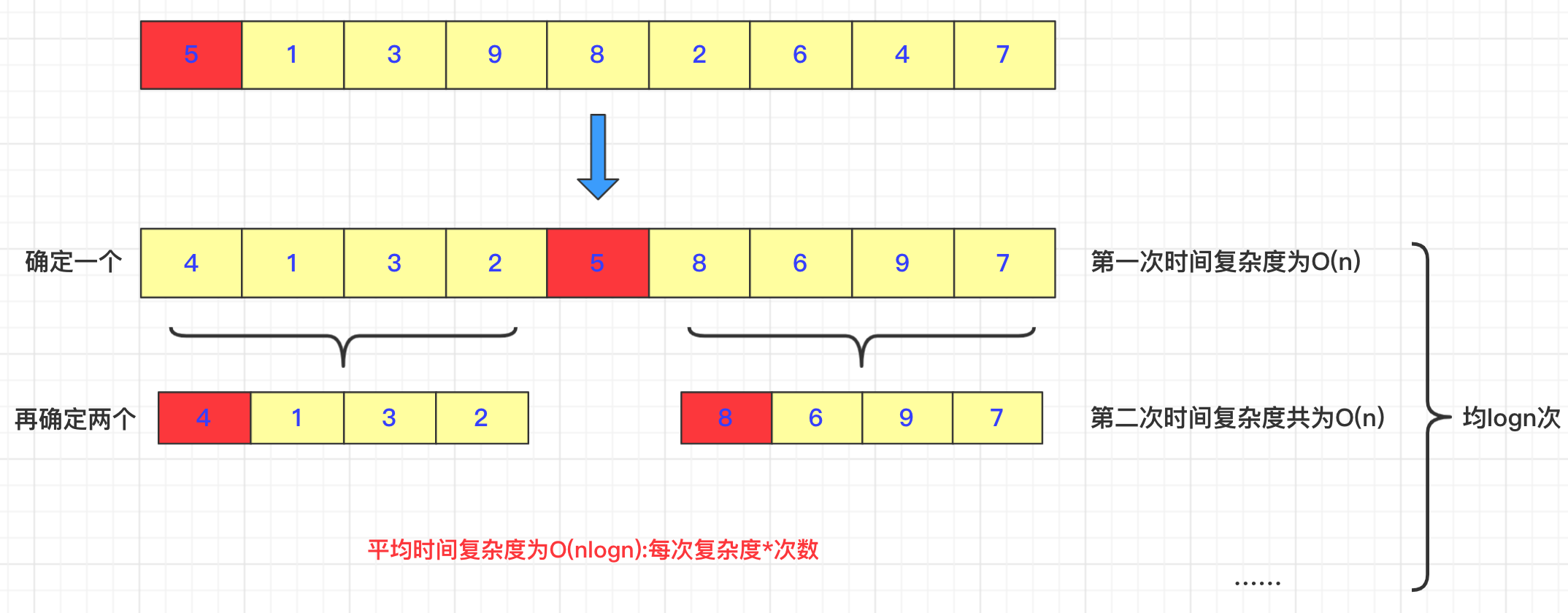
2.快速排序
算法描述
快速排序由于排序效率在同为O(N*logN)的几种排序方法中效率较高,因此经常被采用,再加上快速排序思想—-分治法也确实实用,因此很多软件公司的笔试面试,很多知名IT公司都喜欢考这个,还有大大小的程序方面的考试如软考,考研中也常常出现快速排序的身影。
排序算法的思想非常简单,在待排序的数列中,我们首先要找一个数字作为基准数(这只是个专用名词)。为了方便,我们一般选择第 (1 或最后一个)数字作为基准数(其实选择第几个并没有关系)。接下来我们需要把这个待排序的数列中小于基准数的元素移动到待排序的数列的左边,把大于基准数的元素移动到待排序的数列的右边。这时,左右两个分区的元素就相对有序了;接着把两个分区的元素分别按照上面两种方法继续对每个分区找出基准数,然后移动,直到各个分区只有一个数时为止。
动图演示
(点击查看)
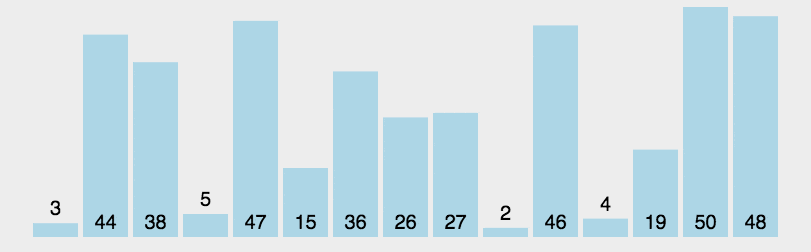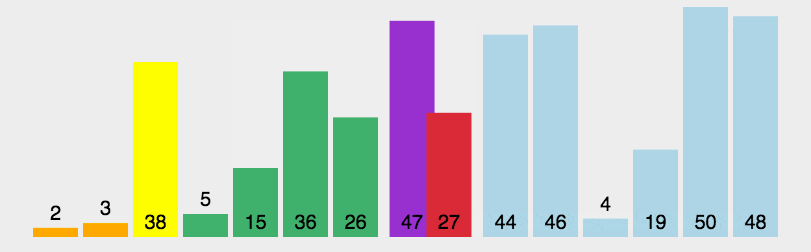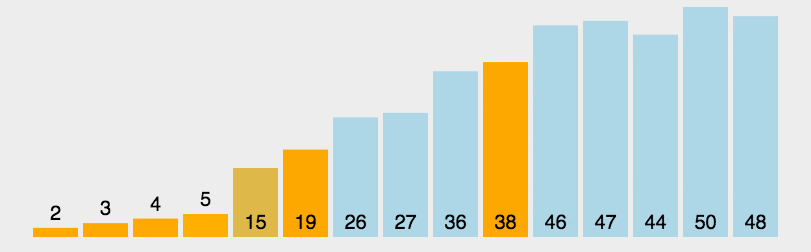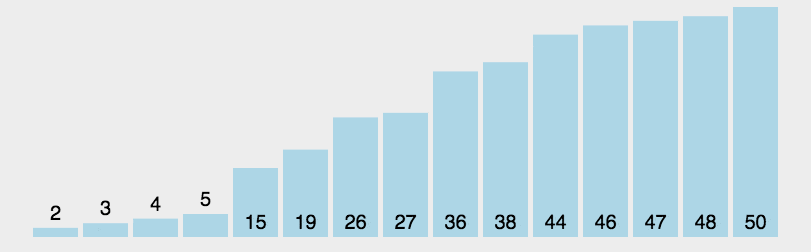
代码实例
从算法的描述和动图的演示,我们可以将每次在找小于等于和大于该基数的过程称作partition过程,我们可以利用插入排序的思想去模拟这个过程,从左到右去维护一个小于等于基数的区间,从而达到一个partition的一个过程。如图:

先定义一个用于交换的方法,以便复用:
public static void swap(int[] nums,int i,int j){
int temp=nums[i];
nums[i]=nums[j];
nums[j]=temp;
}
代码实例1
public static void quickSort1(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
process1(arr, 0, arr.length - 1);
}
public static void process1(int[] arr, int L, int R) {
if (L >= R) {
return;
}
// L..R partition arr[R] [ <=arr[R] arr[R] >arr[R] ]
int M = partition(arr, L, R);
process1(arr, L, M - 1);
process1(arr, M + 1, R);
}
// arr[L..R]上,以arr[R]位置的数做划分值
// <= X > X
// <= X X
public static int partition(int[] arr, int L, int R) {
if (L > R) {
return -1;
}
if (L == R) {
return L;
}
int lessEqual = L - 1;
int index = L;
while (index < R) {
if (arr[index] <= arr[R]) {
swap(arr, index, ++lessEqual);
}
index++;
}
swap(arr, ++lessEqual, R);
return lessEqual;
}
快速排序的时间复杂度为O(logn),并且不具备稳定性,在最坏的情况下快速排序是会回退到时间复杂度为O(n²)的时间复杂度。为什么这么说呢?我们回到partation过程,倘若数据存在以下情况:
- 数组已经是正序(same order)排过序的。
- 数组已经是倒序排过序的。
- 所有的元素都相同(1、2)的特殊情况。
经过
partation过程基数为最大或者最小数字,那么所有数都划分到一个序列去了 时间复杂度为O(n²)。
优化一:
因此我们可以选取一个数据中的随机值和基数位置的值进行交换,从而大大的避免了最坏情况的发生。
优化二:
并且我们还可以在实例1中进行进一步优化,每次partation过程都是维护小于等于的区间,那么在等于基数值的部分是会重复的计算。因此可以去维护两个区间一个小于区间、一个大于区间,在partation过程返回的就是一个小于基数的边界值和一个大于基数的边界值,这样就可以使等于基数值的部分不再进行重复的计算。
代码实例2
public static void quickSort2(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
process3(arr, 0, arr.length - 1);
}
public static void process2(int[] arr, int L, int R) {
if (L >= R) {
return;
}
swap(arr, L + (int) (Math.random() * (R - L + 1)), R);
int[] equalArea = netherlandsFlag(arr, L, R);
process3(arr, L, equalArea[0] - 1);
process3(arr, equalArea[1] + 1, R);
}
//partation过程
public static int[] netherlandsFlag(int[] arr, int L, int R) {
if (L > R) { // L...R L>R
return new int[] { -1, -1 };
}
if (L == R) {
return new int[] { L, R };
}
int less = L - 1; // < 区 右边界
int more = R; // > 区 左边界
int index = L;
while (index < more) { // 当前位置,不能和 >区的左边界撞上
if (arr[index] == arr[R]) {
index++;
} else if (arr[index] < arr[R]) {
// swap(arr, less + 1, index);
// less++;
// index++;
swap(arr, index++, ++less);
} else { // >
swap(arr, index, --more);
}
}
swap(arr, more, R); // <[R] =[R] >[R]
return new int[] { less + 1, more };
}
最终优化的代码就完成了,快速排序是十分重要的,尤其是它的partation过程。