
一、Caffeine简介
最近在学习咖啡因缓存,也阅读了咖啡因缓存的部分源码学到了一些知识,这里分享给大家,本篇主要介绍咖啡因缓存的基本使用,源码解析写在后续篇章中,言归正传下面介绍下咖啡因缓存。在项目开发中,在多线程高并发场景中往往是离不开cache的,需要根据不同的应用场景来需要选择不同的cache,比如分布式缓存如redis、memcached,还有本地(进程内)缓存如ehcache、GuavaCache、Caffeine。在平时的业务场景中缓存也通常作为一个二级缓存来减小频繁访问分布式缓存的网络性能消耗,同时也能减轻分布式缓存的压力。Caffeine号称本地缓存之王:咖啡因是一个高性能、接近最佳的缓存库,按 Caffeine Github 文档描述,Caffeine 是基于 JAVA 8 的高性能缓存库。并且在 spring5 (springboot 2.x) 后,spring 官方放弃了 Guava,而使用了性能更优秀的 Caffeine 作为默认缓存组件。
二、性能比较
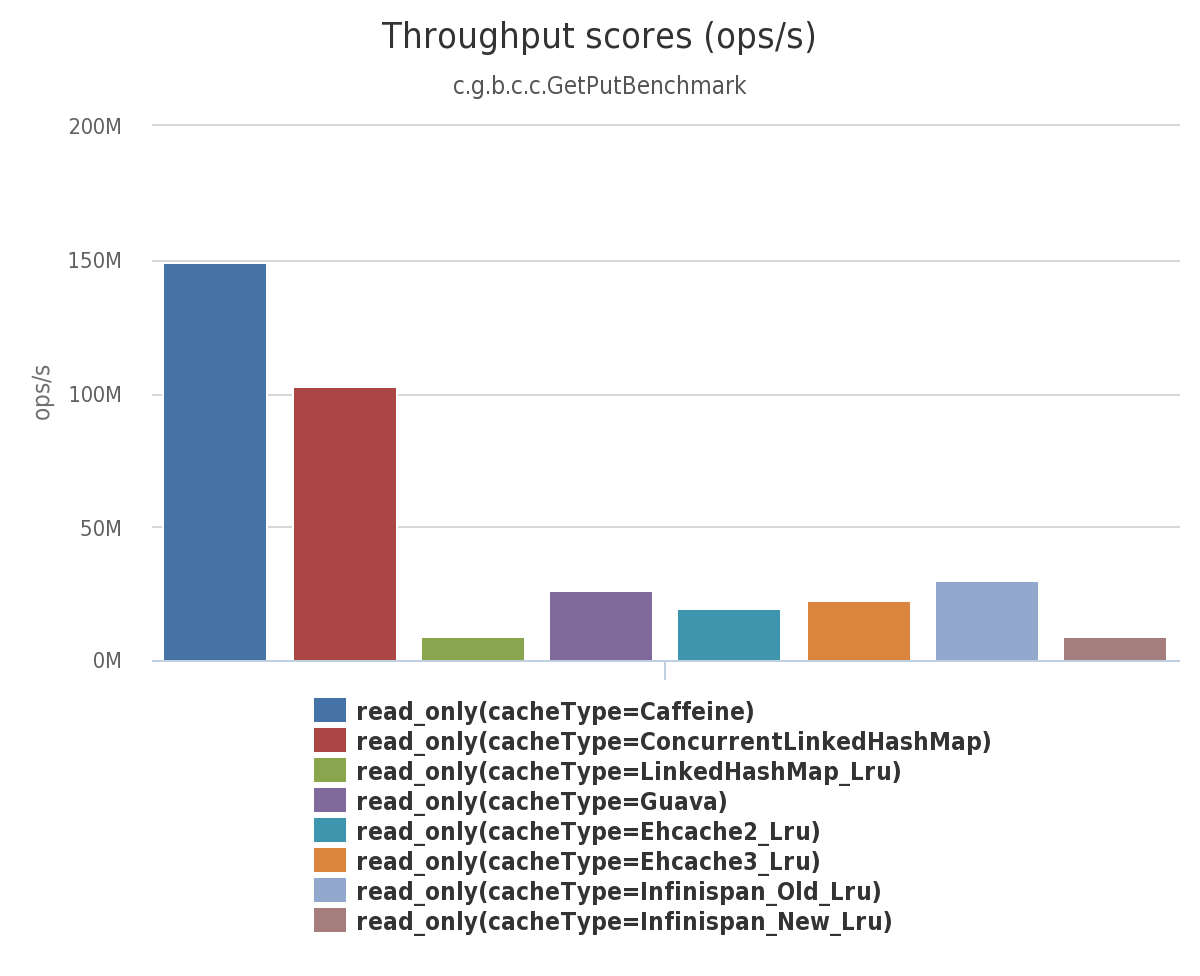
- 多缓存间同时读比较
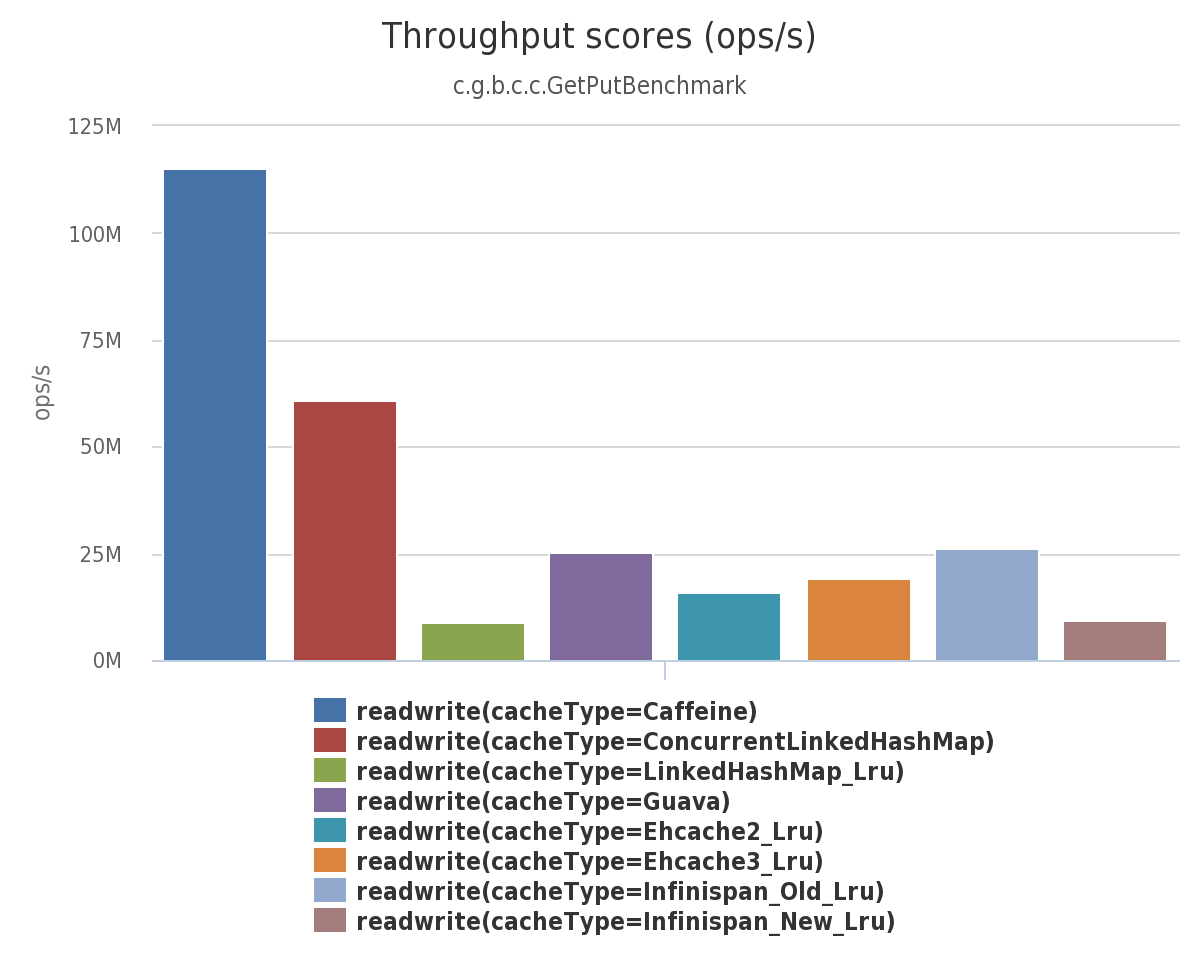
- 多缓存同时读写比较
- 多缓存写比较
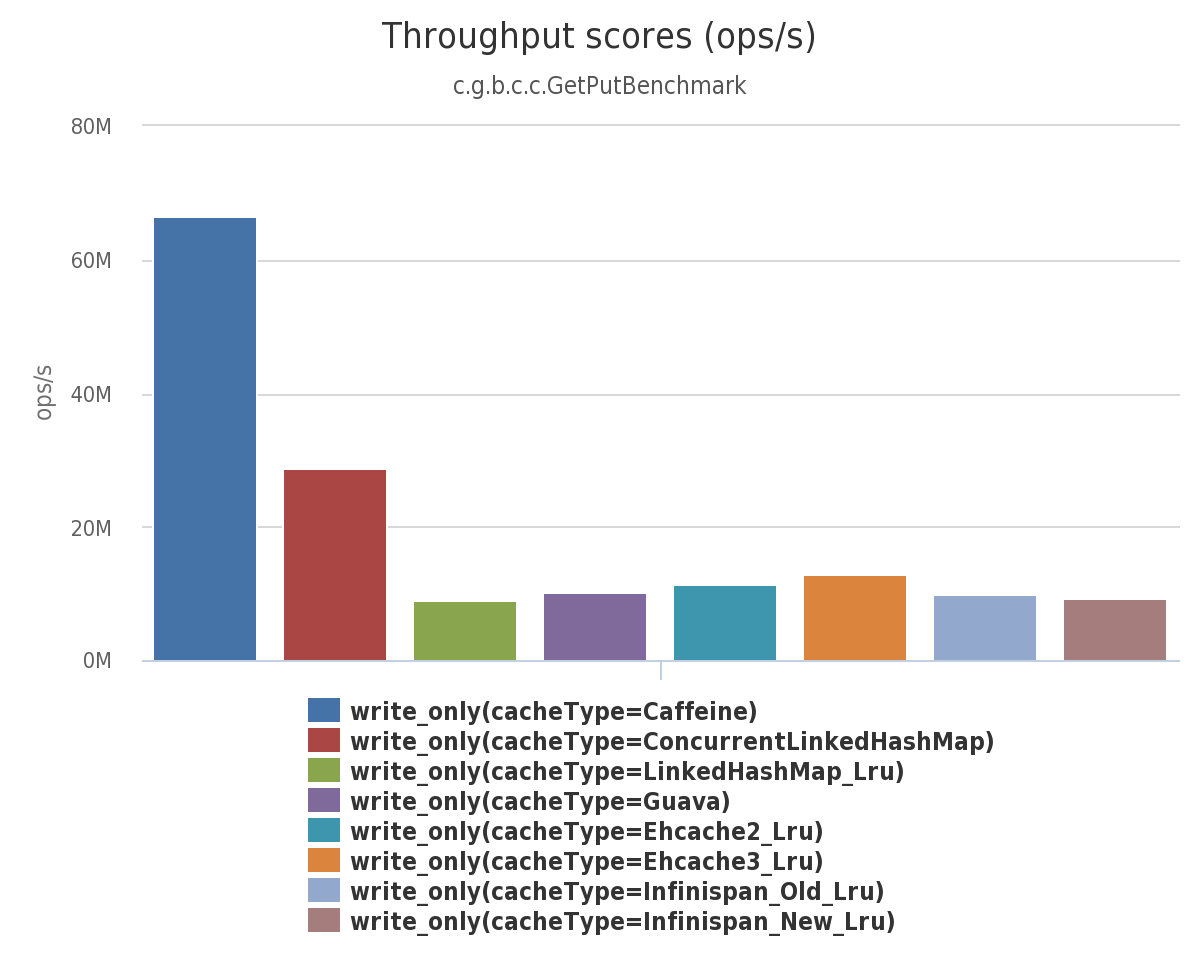
通过这几种场景的比较我们发现Caffeine是完全优于其他的缓存。
三、基本使用
- 在maven中添加依赖(新版本已经到3.X.X)
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.9.3</version>
</dependency>
- 基本使用测试类
public class CaffeineTest {
public static void main(String[] args) throws InterruptedException {
LoadingCache<String,Integer> cache= Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(1, TimeUnit.DAYS)
.removalListener(new RemovalListener<String, Integer>() {
@Override
public void onRemoval(@Nullable String key, @Nullable Integer value, @NonNull RemovalCause cause) {
System.out.println("移除了--"+key+"值为--"+value+"原因--"+cause);
}
})
.build(new CacheLoader<String, Integer>() {
@Override
public @Nullable Integer load(@NonNull String key) throws Exception {
//可以写作从分布式缓存中获取代码 例如redis
return null;
}
});
cache.put("1",2);
cache.get("1");
}
}
配置参数(这里介绍下测试类的配置参数,详细的配置参数会在下面进行详细介绍):
这里我使用的是LoadingCache即自动加载,使用这个自动加载的Cache需要在build中new一个CacheLoader从某个源中自动加载
-
maximumSize();最大key的数量
-
expireAfterWrite();写后多久过期
-
removalListener();移除监听器
四、策略及配置详细介绍
1.过期策略
过期策略就是指我们设置的缓存信息,经过多久的时间在缓存中失效。它提供了三种Api:
- expireAfterWrite():代表着写了之后多久过期。
- expireAfterAccess(): 代表着最后一次访问了之后多久过期。
- expireAfter():在expireAfter中需要自己实现Expiry接口,这个接口支持create,update,以及access了之后多久过期。注意这个API和前面两个API是互斥的。这里和前面两个API不同的是,需要你告诉缓存框架,他应该在具体的某个时间过期(也就是自定义的策略)。
这里我们发现,它的过期时间是针对所有key的,能不能像redis一样为特定的key指定特定的过期时间呢?其实作者提供了一种高级写法需要和上面提到的expireAfter()方法一起使用,下面贴出例子:
public static void main(String[] args) throws InterruptedException {
LoadingCache<String,Integer> cache= Caffeine.newBuilder()
.maximumSize(1000)
.expireAfter(new Expiry<Object, Object>() {
@Override
public long expireAfterCreate(@NonNull Object key, @NonNull Object value, long currentTime) {
return currentTime;
}
@Override
public long expireAfterUpdate(@NonNull Object key, @NonNull Object value, long currentTime, @NonNegative long currentDuration) {
return currentDuration;
}
@Override
public long expireAfterRead(@NonNull Object key, @NonNull Object value, long currentTime, @NonNegative long currentDuration) {
return currentDuration;
}
})
.build(new CacheLoader<String, Integer>() {
@Override
public @Nullable Integer load(@NonNull String key) throws Exception {
//可以写作从分布式缓存中获取代码 例如redis
return null;
}
});
cache.policy().expireVariably().ifPresent(policy -> {
policy.put("test1", 2, 13, TimeUnit.SECONDS);
policy.put("test2", 2, 10, TimeUnit.SECONDS);
});
}
2.更新策略
- refreshAfterWrite():写后多久进行缓存的自动刷新。
示例里面的代码我们需要建立一个CacheLodaer来进行刷新,这里是同步进行的,也可以通过buildAsync方法进行异步构建。在实际业务中这里可以把我们代码中的mapper或者redis中数据传入进去,进行数据源的刷新。但是实际使用中,你设置了一天刷新,但是一天后你发现缓存并没有刷新。这是因为没有对缓存进行访问,就不会触发它的更新策略后续在源码分析中也有分析。
3.加载策略
咖啡因提供了三种加载策略:手动、同步、异步。
其加载策略实际上的作用就是当你获取到key的时候,缓存中并没有这个key,这时缓存会自动帮你将这个key加载进redis中,并且我们可以自定义值。而这三种不同的加载策略分别对应着Cache类、LoadingCache类、AsyncLoadingCache类,这里很好理解手动加载就是需要我们手动的使用方法触发加载,自动加载就是Cache检测到没有这个key时自动为我们加载,而异步加载就是利用了一个线程池为不存在的key进行一个异步加载。
- 手动
public static void main(String[] args) {
Cache<String, Integer> cache = Caffeine.newBuilder()
.maximumSize(100)
.build();
cache.get("test",policy->1);
}
这里自动加载实际上就是通过自己实现了一个function()函数接口,自定义加载不存在key的value;
- 自动
public static void main(String[] args) {
LoadingCache<String,Integer> cache= Caffeine.newBuilder()
.maximumSize(100)
.build(new CacheLoader<String, Integer>() {
@Override
public @Nullable Integer load(@NonNull String key) throws Exception {
//这里自动加载不存在key的值
return 0;
}
});
cache.get("22");
通过CacheLoader自动加载不存在的key
- 异步
public static void main(String[] args) throws ExecutionException, InterruptedException {
AsyncLoadingCache<String,Integer> cache = Caffeine.newBuilder()
.maximumSize(1000)
// 你可以选择: 去异步的封装一段同步操作来生成缓存元素
.buildAsync(new CacheLoader<String, Integer>() {
@Override
public @Nullable Integer load(@NonNull String key) throws Exception {
return 0;
}
});
CompletableFuture<Integer> integerCompletableFuture = cache.get("22");
Integer temp = integerCompletableFuture.get();
System.out.println(temp);
}
AsyncLoadingCache是继承自LoadingCache类的,异步加载使用Executor去调用方法并返回一个CompletableFuture。异步加载缓存使用了响应式编程模型。
4.驱逐策略
- maximumSize():key设置的最大数量
- maximumWeigtht():设置权重大小(也可作为内存)
在淘汰策略上Caffeine是可以根据key的数量和权重大小来设置淘汰策略的,但在源码中其实都通过权重计算,在没有重写Weigher()方法时,默认会生成一个Weigher.singletonWeigher()。在put方法时就会调用这个Weigher的weight方法来计算权重而singletonWeigher的weight每次都将权重记为1,所次每次增加的权重也就是1,因此我们在设置maximumWeigtht时需要重写weigher(new Weigher<Object, Object>()方法生成一个自定义的权重计算器。
LoadingCache<String,Integer> cache = Caffeine.newBuilder()
.maximumWeight(1000)
.weigher(new Weigher<Object, Object>() {
@Override
public @NonNegative int weigh(@NonNull Object key, @NonNull Object value) {
//这里计算值在堆空间的内存
return Math.toIntExact(RamUsageEstimator.shallowSizeOf(value));
}
}).build(new CacheLoader<String, Integer>() {
@Override
public @Nullable Integer load(@NonNull String key) throws Exception {
return null;
}
});
- softValues():基于引用,我们可以将缓存的驱逐配置成基于垃圾回收器。当没有任何对对象的强引用时,使用 WeakRefence 可以启用对象的垃圾收回收。SoftReference 允许对象根据 JVM 的全局最近最少使用(Least-Recently-Used)的策略进行垃圾回收。
5.同步Writer(3版本已移除)
- writer()
在学习源码的过程中对于源码中这个Writer的作用一直不清晰,也查阅了一些资料有的说启到缓冲作用、同步监听器、还有的说可以用作输出。因此我给作者发了个邮件(ps:没想到外国大佬秒回)
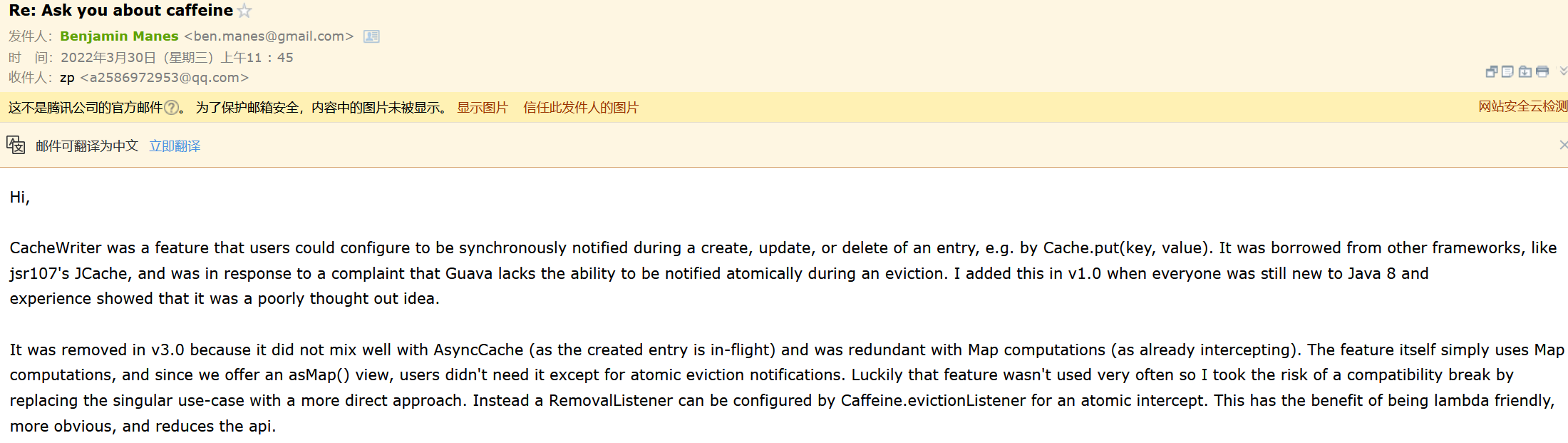
其实作者的意思设计的初衷是它就是做同步监听的作用,并且它不能很好的和异步的AsyncLoadingCache整合因此就删除了
6.监听策略
- removalListener():用来监听缓存的移除,如果我们需要在缓存被移除的时候,得到通知产生回调,并做一些额外处理工作。这个时候RemovalListener就派上用场了,我们在使用这个方法时需要new 一个 RemovalListener 。
LoadingCache<String, Integer> cache = Caffeine.newBuilder()
.maximumWeight(1000)
.removalListener(new RemovalListener<Object, Object>() {
@Override
public void onRemoval(@Nullable Object key, @Nullable Object value, @NonNull RemovalCause cause) {
System.out.println("移除了--" + key + "值为--" + value + "原因--" + cause);
}
}).build(new CacheLoader<String, Integer>() {
@Override
public @Nullable Integer load(@NonNull String key) throws Exception {
return null;
}
});
这里的cause有三种:
- 驱逐(eviction):由于满足了某种驱逐策略,后台自动进行的删除操作
- 无效(invalidation):表示由调用方手动删除缓存
- 移除(removal):监听驱逐或无效操作的监听器
7.统计
- recordStats():提供了统计功能,包括:未命中数量、返回命中缓存的总数、缓存驱逐的数量、加载新值所花费的平均时间等。
LoadingCache<String, Integer> cache = Caffeine.newBuilder()
.maximumWeight(1000)
.recordStats()
.build(new CacheLoader<String, Integer>() {
@Override
public @Nullable Integer load(@NonNull String key) throws Exception {
return null;
}
});
CacheStats stats = cache.stats();
stats.hitCount();//命中数量
stats.missCount();//未命中数量
stats.evictionCount();//淘汰驱逐数量
stats.averageLoadPenalty();//加载新值所花费的平均时间
五、总结
本文主要介绍了Caffeine的介绍以及不同策略的配置,大家可以在不同的业务中使用不同的配置。后面给大家分享下主体的源码解析,以便在不同的业务场景下对其进行一些改动达到业务中的要求,也便于排查错误。同时我也封装了一套自定义的Caffine工具,基于内存大小的驱逐策略以及对不同key设置不同的过期时间。我把它放在我的GitHub上如果有需要请自取:zpbaba/myCaffine (github.com)