
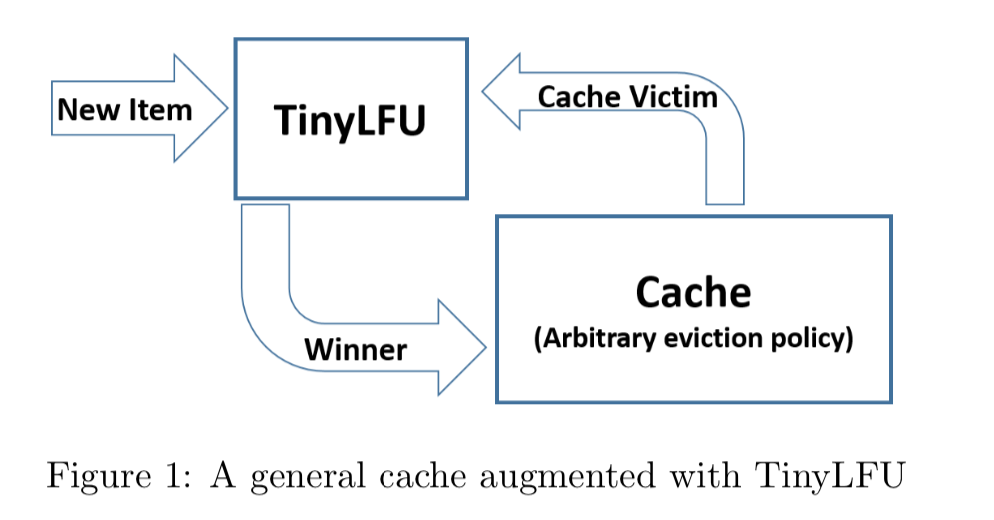
一、前文回溯
在上篇文章中我为大家分享了Caffeine的get和put方法。实际上判断一个缓存好坏的最核心指标就是这个缓存的命中率,影响缓存的命中率有很多的因素比如:淘汰策略、过期策略、缓存容量等因素。因此在这篇文章中将为大家刨析Caffeine的淘汰策略、过期策略进行讲解,然后再将上篇文章中的未讲解的maintenance()进行分析,使大家能够对Caffeine整体的原理有一定的了解。
二、淘汰策略
缓存淘汰算法的作用是在有限的资源内,尽可能识别出哪些数据在短时间会被重复利用,从而提高缓存的命中率,在我的博客中也写过LRU和LFU淘汰算法的简单实现,如果有不了解的可以看一下那篇文章。言归正传那么咖啡因的淘汰算法也是LRU和LFU吗?答案是否定的,咖啡因并没有采用这两种淘汰算法,我们先来看看这两种淘汰算法会有什么样的缺点:
- LRU实现简单,在一般情况下能够表现出很好的命中率,是一个“性价比”很高的算法,平时也很常用。虽然LRU对突发性的稀疏流量(sparse bursts)表现很好,但是他有个最大的缺点就是应对不了“洗数据”。举个例子:有一大批突发的全量数据进行遍历,那么历史的"热点记录"就会被冲刷走。
- LFU如果数据的分布在一段时间内是固定的话,那么LFU可以达到最高的命中率。但是LFU有两个缺点,首先他要对每个记录项维护频率信息,每次访问时都要更新频率,不管时间还是空间都会有开销。其次,LFU无法应对突发性的稀疏流量,因为以前经常访问的数据已经占用了缓存,偶然的流量不太可能会保留下来,这就形成了LFU的第二个缺点。
经过分析发现哪种淘汰策略可能都会有一些各自的问题,而Caffeine采用的是一种W-TinyLFU的缓存淘汰算法。从名字种我们可以看出它也是一种LFU算法那么W-TinyLFU是如何解决LFU的缺点呢?W-TinyLFU实际上是从TinyLFU演进出来的算法,TinyLFU是一个LFU的优化算法是专门为了解决LFU算法的弊端而设计出来的。
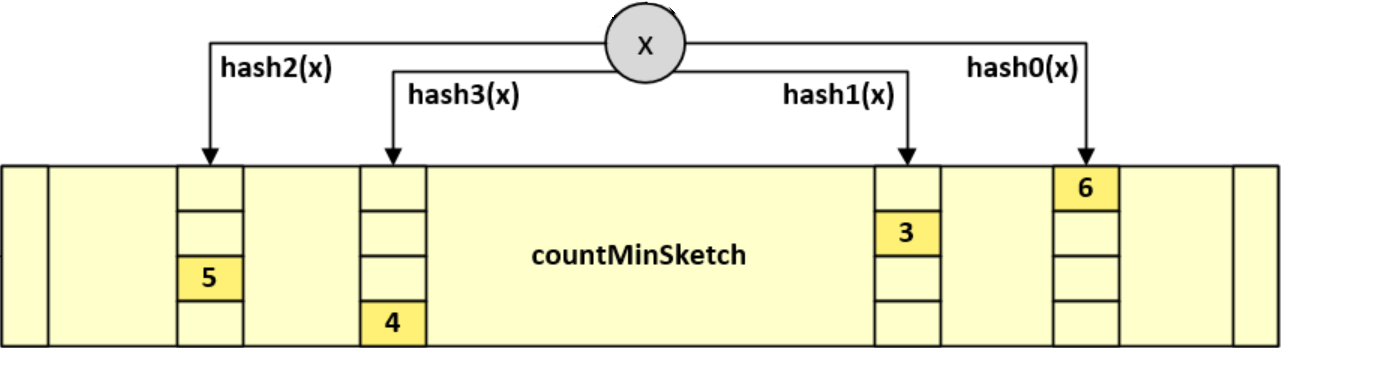
解决第一个弊端TinyLFU采用Count–Min Sketch统计频率算法,我们知道采用传统的LFU对频率进行统计占用了大量的空间,那么如何通过对key的频率统计花费较小的空间呢?不需要精确的统计,只需要一个近似值就可以了,怎么样,这样场景是不是很熟悉,使用更小的空间来进行key的命中获取,相信大家已经想到布隆过滤器了。Count–Min Sketch的原理跟Bloom Filte比较类似,只不过Bloom Filter只有0和1的值,那么你可以把Count–Min Sketch看作是“数值”版的Bloom Filter。在Caffeine里将每个key的最大命中次数上限设为15,用4个bit表示。每个long为64位,可分为16个4bit,这样每个long型整数可以保存16个频率的信息。这里我们只需要关注Caffeine是如何使用的这个算法,Caffeine对这个算法的实现在FrequencySketch类。
下面我们来分析一下Caffine源码的频次统计具体做法:
1.存储:用一个大Long型一维数组保存所有数据,每个数组元素包括16个分段(下面将每个数组元素称为一个slot保存一次频率下标,每个4bit分段称为一个counter保存一次频率信息)。
2.计算:使用hash算法将每个key的频次映射到某个Counter中。并借鉴BloomFilter思想,用多种hash算法降低hash重复带来的误差。
3.定位:每个key计算一个hash值,再用hash值计算出4种index,表示在哪些slot中;用hash值计算出在4个counter中的位置,每个slot中的counter下标相差1位,counter下标从右到左为0-16。
4.累加:每次命中后将4个counter值加1,最多15(咖啡因认为15已经是热点数据了)。
5.选择:由于每个元素的hash值都可能跟其他key相同,所以每次频次加1时,可能将其他key的频次加1。所以取这4个key的最小值最为该key的频次。
知道了怎么解决第一个弊端那么是如何解决第二个弊端的呢?那就是尽量保持数据相对"新鲜":达到一定条件时,在FrequencySketch频次记录类中就将所有key的命中频次减半(降频)。并且在具体的淘汰流程中当有新的记录插入时,可以让它跟老的记录进行“PK”,输者就会被淘汰,这样一些老的、不再需要的记录就会被剔除。话不多说上我们先来看下FrequencySketch类的代码
final class FrequencySketch<E> {
//hash种子,用来计算4个不同的hash值,对应四次哈希
static final long[] SEED = { // A mixture of seeds from FNV-1a, CityHash, and Murmur3
0xc3a5c85c97cb3127L, 0xb492b66fbe98f273L, 0x9ae16a3b2f90404fL, 0xcbf29ce484222325L};
static final long RESET_MASK = 0x7777777777777777L;
static final long ONE_MASK = 0x1111111111111111L;
int sampleSize;
//table的长度size一般为2的n次方,而tableMask为size-1,这样就可以通过&操作来模拟取余操作。
//hash&tableMask相当于取模,得到slot的index
int tableMask;
//记录frequency的一维数组
long[] table;
//存储counter和
int size;
/**
* Creates a lazily initialized frequency sketch, requiring {@link #ensureCapacity} be called
* when the maximum size of the cache has been determined.
*/
@SuppressWarnings("NullAway.Init")
public FrequencySketch() {}
/**
* Initializes and increases the capacity of this <tt>FrequencySketch</tt> instance, if necessary,
* to ensure that it can accurately estimate the popularity of elements given the maximum size of
* the cache. This operation forgets all previous counts when resizing.
*初始化并增加这个<tt>FrequencySketch</tt>实例的容量,如果需要时(若maximumSize=0,table长度为1(无界缓存,所有数据都被记录下来,也就无需记录每个数据的频次了))
* 确保它能准确估计出给定元素的流行度的最大尺寸缓存。 此操作在调整大小时忘记以前的所有计数。
* 比如:
* maximumSize=0,table长度为1,sampleSize=Integer.MAX_VALUE
* maximumSize=10,table长度为16,sampleSize=160
* maximumSize=100,table长度为128,sampleSize=1280
*
* @param maximumSize the maximum size of the cache
*/
public void ensureCapacity(@NonNegative long maximumSize) {
requireArgument(maximumSize >= 0);
//数组长度最大为Integer.MAX_VALUE的二分之一,也就是2147483647/2=1073741823,大概10.7亿
int maximum = (int) Math.min(maximumSize, Integer.MAX_VALUE >>> 1);
if ((table != null) && (table.length >= maximum)) {
return;
}
table = new long[(maximum == 0) ? 1 : Caffeine.ceilingPowerOfTwo(maximum)];
//tableMask=数组长度减1
tableMask = Math.max(0, table.length - 1);
sampleSize = (maximumSize == 0) ? 10 : (10 * maximum);
if (sampleSize <= 0) {
sampleSize = Integer.MAX_VALUE;
}
size = 0;
}
/**
* Returns if the sketch has not yet been initialized, requiring that {@link #ensureCapacity} is
* called before it begins to track frequencies.
*/
public boolean isNotInitialized() {
return (table == null);
}
/**
* Returns the estimated number of occurrences of an element, up to the maximum (15).
*
* @param e the element to count occurrences of
* @return the estimated number of occurrences of the element; possibly zero but never negative
*/
//计算频率方法
@NonNegative
public int frequency(E e) {
if (isNotInitialized()) {
return 0;
}
//对key进行二次哈希使哈希值更加散列
int hash = spread(e.hashCode());
//如上文所说,Caffeine把一个long的64bit划分成16个等分,每一等分4个bit。
//start为counter下标,这个算法start只可能为0 4 8 12的其中一种,对应流程中第二步,通过计算Counter在一个long类型的位置
int start = (hash & 3) << 2;
int frequency = Integer.MAX_VALUE;
//循环四次,分别获取在table数组中不同的下标位置 对应流程第三步,对key的位置定位和四个Counter定位
for (int i = 0; i < 4; i++) {
//通过哈希种子来计算key对应下标
int index = indexOf(hash, i);
//table[index]为当前slot的long整数。
//假设start为4,二进制为0100,table[index]的二进制为0100 1010... 1101 0011 1000 0011 1001
//(start + i) << 2 左移两位0001 0000,也就是十进制16,其实就是从右数,下标为4的counter的二进制的右边第一位,这个counter就是1101
//(table[index] >>> 16也就是0000 0000 0000 0000 0100 1010... 1101
//oxfL也就是15,二进制为0000 0000...0000 1111,跟"0000 0000 0000 0000 0100 1010... 1101"相与,就是只保留后4位,1101,也就是这个counter的值=该元素在该位置的频次
int count = (int) ((table[index] >>> ((start + i) << 2)) & 0xfL);
frequency = Math.min(frequency, count);
}
return frequency;
}
/**
* Increments the popularity of the element if it does not exceed the maximum (15). The popularity
* of all elements will be periodically down sampled when the observed events exceed a threshold.
* This process provides a frequency aging to allow expired long term entries to fade away.
*
* @param e the element to add
*/
//增加频率方法
public void increment(E e) {
if (isNotInitialized()) {
return;
}
//同上面计算频率方法
int hash = spread(e.hashCode());
//start为counter下标,这个算法start只可能为0 4 8 12的其中一种,对应流程中第二步,通过计算Counter在一个long类型的位置
int start = (hash & 3) << 2;
//indexOf方法的意思就是,根据hash值和不同种子得到table的下标index
//这里通过四个不同的种子,得到四个不同的下标index
//找出key对应的四个下标
int index0 = indexOf(hash, 0);
int index1 = indexOf(hash, 1);
int index2 = indexOf(hash, 2);
int index3 = indexOf(hash, 3);
//上面说过counter在四个下标的比特位是连续的
//尝试在每个counter上加1,最多15
boolean added = incrementAt(index0, start);
added |= incrementAt(index1, start + 1);
added |= incrementAt(index2, start + 2);
added |= incrementAt(index3, start + 3);
//这里用做解决第二个弊端,
if (added && (++size == sampleSize)) {
reset();
}
}
/**
* Increments the specified counter by 1 if it is not already at the maximum value (15).
*
* @param i the table index (16 counters)
* @param j the counter to increment
* @return if incremented
*/
//增加四个index的频率
boolean incrementAt(int i, int j) {
//这个j表示Counter在16个等分的下标,那么offset就是相当于在64位中的下标
int offset = j << 2;
//mask为掩码,counter的那4个bit,在mask中相同位置的4bit为1111,其他位置为0。
long mask = (0xfL << offset);
if ((table[i] & mask) != mask) {
//(table[i] & mask) != mask,表示那4bit不全为1,也就是不等于15
//1L也就是0001,左移offset位,也就是将这4位移到跟counter相同的位置,然后相加。
//比如table[index]的二进制为0100 1010...1101 0011 1000 0011 1001,offset=12,counter的4bit为1101,十进制=13
//1L << offset的结果为 0000 0000...0001 0000 0000 0000 0000。相加后1101变成1110,十进制=14
//虽然counter只加了1,但table[i]加了"1 0000 0000 0000 0000",十进制507376
table[i] += (1L << offset);
return true;
}
return false;
}
/** Reduces every counter by half of its original value. */
//频率减半
void reset() {
int count = 0;
for (int i = 0; i < table.length; i++) {
//16个counter中频次为奇数的个数
//table[i] >>> 1,整体右移1位,其中每4个bit也右移1位,相当于除2。但每个counter的高位是上一个bit的低位,可能为1
//& RESET_MASK,抹去新counter的最高位,保留低三位。最终实现每个counter除2
// 1100 1001 0001 0010
// 右移1位 0110 0100 1000 1001
// 相与后 0110 0100 0000 0001
count += Long.bitCount(table[i] & ONE_MASK);
table[i] = (table[i] >>> 1) & RESET_MASK;
}
size = (size - (count >>> 2)) >>> 1;
}
/**
* Returns the table index for the counter at the specified depth.
*
* @param item the element's hash
* @param i the counter depth
* @return the table index
*/
int indexOf(int item, int i) {
long hash = (item + SEED[i]) * SEED[i];
hash += (hash >>> 32);
return ((int) hash) & tableMask;
}
/**
* Applies a supplemental hash function to a given hashCode, which defends against poor quality
* hash functions.
*/
int spread(int x) {
x = ((x >>> 16) ^ x) * 0x45d9f3b;
x = ((x >>> 16) ^ x) * 0x45d9f3b;
return (x >>> 16) ^ x;
}
}
为什么增加一个Window?
Caffeine通过测试发现TinyLFU在面对突发性的稀疏流量(sparse bursts)时表现很差,因为新的记录(new items)还没来得及建立足够的频率就被剔除出去了,这就使得命中率下降。于是Caffeine采用了Window Tiny LFU来解决这种情况。通过增加一个缓存区(即Window Cache),当有新的记录插入时,会先在window区呆一下,就可以避免对突发性的稀疏流量时表现很差的问题。
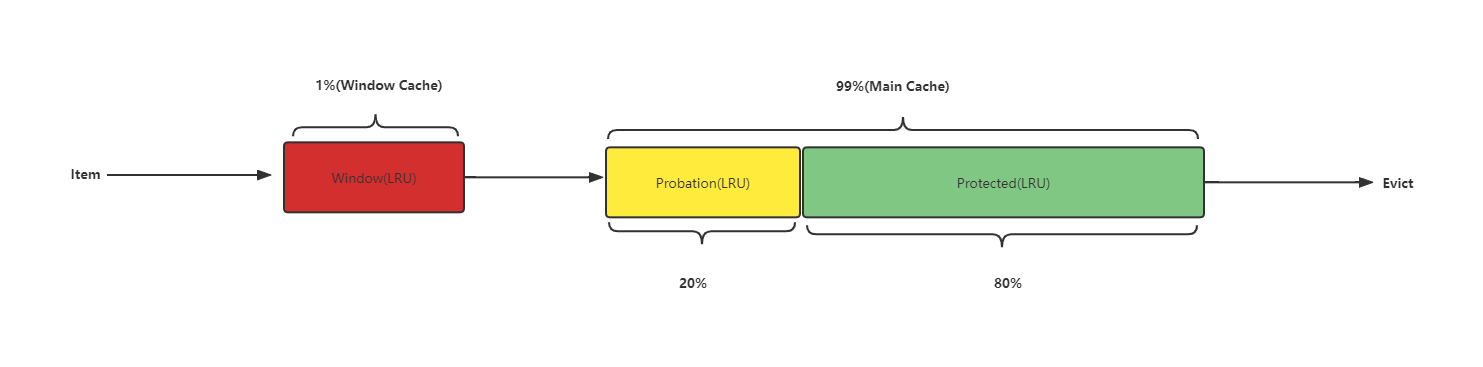
淘汰流程具体步骤:
- 1.当window区满了,就会根据LRU把candidate(即淘汰出来的元素)放到probation区。
- 2.如果probation区也满了,就把candidate(新从Window区插入的)和probation区将要淘汰的元素victim两者进行频率的比较,胜者留在probation,输者就要被淘汰了。
上面我们说了具体针对频率记录的FrequencySketch类,下面我们具体说下整体源码中的淘汰流程:
void evictEntries() {
if (!evicts()) {
return;
}
//先清Window区,即在window区选出要淘汰的数据
int candidates = evictFromWindow();
//再清主存区
evictFromMain(candidates);
}
//调整Window区内存
@GuardedBy("evictionLock")
int evictFromWindow() {
int candidates = 0;
//获取当前window区队首节点
Node<K, V> node = accessOrderWindowDeque().peek();
//若当前window区内存不足
while (windowWeightedSize() > windowMaximum()) {
// The pending operations will adjust the size to reflect the correct weight
if (node == null) {
break;
}
//获取当前节点在访问顺序队列的下一个节点
Node<K, V> next = node.getNextInAccessOrder();
if (node.getPolicyWeight() != 0) {
node.makeMainProbation();
//从Window区队列移除节点
accessOrderWindowDeque().remove(node);
//放到Probation队列中
accessOrderProbationDeque().add(node);
candidates++;
//重置Window区大小
setWindowWeightedSize(windowWeightedSize() - node.getPolicyWeight());
}
node = next;
}
return candidates;
}
void evictFromMain(int candidates) {
int victimQueue = PROBATION;
//从Probation区中拿出头节点
Node<K, V> victim = accessOrderProbationDeque().peekFirst();
//从Probation区中拿出尾节点
Node<K, V> candidate = accessOrderProbationDeque().peekLast();
while (weightedSize() > maximum()) {
......
//比较频次
if (admit(candidateKey, victimKey)) {
Node<K, V> evict = victim;
victim = victim.getNextInAccessOrder();
evictEntry(evict, RemovalCause.SIZE, 0L);
candidate = candidate.getPreviousInAccessOrder();
}
}
}
boolean admit(K candidateKey, K victimKey) {
//victim是probation queue的头部
int victimFreq = frequencySketch().frequency(victimKey);
//candidate是probation queue的尾部,也就是刚从window晋升来的
int candidateFreq = frequencySketch().frequency(candidateKey);
//如果candidateFreq大于victimFreq 则淘汰victimFreq
if (candidateFreq > victimFreq) {
return true;
} else if (candidateFreq <= 5) {
// The maximum frequency is 15 and halved to 7 after a reset to age the history. An attack
// exploits that a hot candidate is rejected in favor of a hot victim. The threshold of a warm
// candidate reduces the number of random acceptances to minimize the impact on the hit rate.
return false;
}
//如果candidateFreq<=victimFreq且candidate大于5,则随机淘汰一个他们中一个
int random = ThreadLocalRandom.current().nextInt();
return ((random & 127) == 0);
}
这里淘汰策略整个流程就完成了,具体怎么删除存储在缓存中的节点,大家有兴趣可以自己看一下。这里为大家分享一下实现W-TinyLFU策略的实现用到的数据结构
//最大的个数限制
long maximum;
//当前的个数
long weightedSize;
//window区的最大限制
long windowMaximum;
//window区当前的个数
long windowWeightedSize;
//protected区的最大限制
long mainProtectedMaximum;
//protected区当前的个数
long mainProtectedWeightedSize;
//下一次需要调整的大小(还需要进一步计算)
double stepSize;
//window区需要调整的大小
long adjustment;
//命中计数
int hitsInSample;
//不命中的计数
int missesInSample;
//上一次的缓存命中率
double previousSampleHitRate;
final FrequencySketch<K> sketch;
//window区的LRU queue(FIFO)
final AccessOrderDeque<Node<K, V>> accessOrderWindowDeque;
//probation区的LRU queue(FIFO)
final AccessOrderDeque<Node<K, V>> accessOrderProbationDeque;
//protected区的LRU queue(FIFO)
final AccessOrderDeque<Node<K, V>> accessOrderProtectedDeque;
三、过期策略
上面聊了一下缓存的淘汰策略,这里我们来聊一下Caffeine的过期策略,从上篇文章中我们知道在Task中根据三种过期策略:写后过期、访问后过期、自定义过期(某个key设置某个过期时间)将这三种策略放到三个不同的队列中:
if (isAlive) {
//放到writeOrderDeque队列||accessOrderWindowDeque队列||放入时间轮
if (expiresAfterWrite()) {
writeOrderDeque().add(node);
}
//如果是需要驱逐的
if (evicts() && (weight > windowMaximum())) {
accessOrderWindowDeque().offerFirst(node);
//如果需要驱逐或者访问后过期策略
} else if (evicts() || expiresAfterAccess()) {
accessOrderWindowDeque().offerLast(node);
}
if (expiresVariable()) {
//放到当前时间轮的链表下
timerWheel().schedule(node);
}
}
对于writeOrderDeque队列和accessOrderWindowDeque(Window区)这种结构就是一个FIFO的队列,这里我们重点来聊一下 timerWheel()时间轮,那什么是时间轮呢?时间轮:时间轮方案将现实生活中的时钟概念引入到软件设计中,主要思路是定义一个时钟周期(比如时钟的12小时)和步长(比如时钟的一秒走一次),当指针每走一步的时候,会获取当前时钟刻度上挂载的任务并执行。
从概念上我们可以了解到时间轮算法正好可以符合针对不同key的过期时间根据时间轮去处理key的过期。而在Caffine中采用了一个多层时间轮的结构:
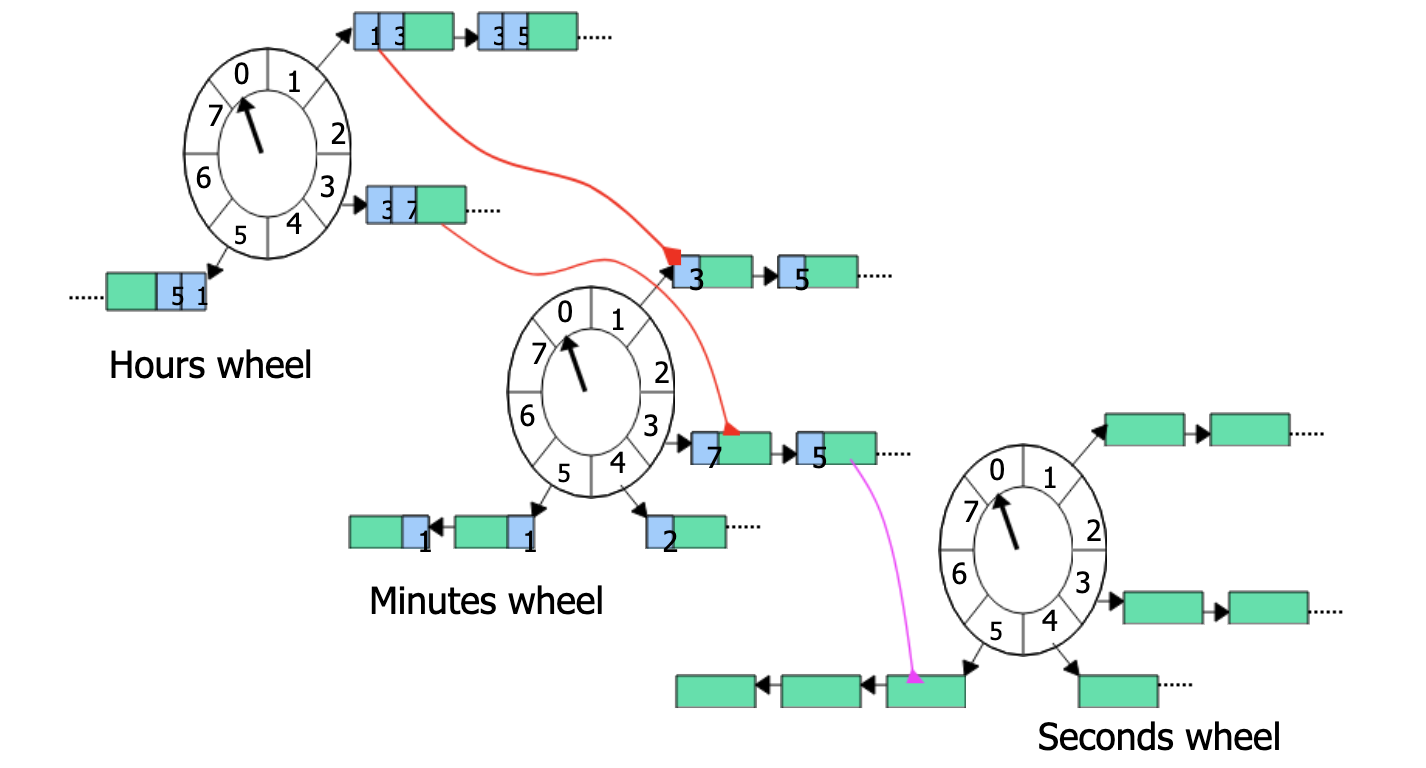
为什么采用多层时间轮呢?当时间跨度很大时,提升单层时间轮的 tickDuration(转度频率)可以减少空转次数,但会导致时间精度变低,层级时间轮既可以避免精度降低,又避免了指针空转的次数。如果有时间跨度较长的定时任务,则可以交给层级时间轮去调度。假设一下一个定时了 3 天,10 小时,50 分,30 秒的定时任务,在 tickDuration = 1s 的单层时间轮中,需要经过:3246060+106060+5060+30 次指针的拨动才能被执行。但在 wheel1 tickDuration = 1 天,wheel2 tickDuration = 1 小时,wheel3 tickDuration = 1 分,wheel4 tickDuration = 1 秒 的四层时间轮中,只需要经过 3+10+50+30 次指针的拨动。(有感兴趣的可以自行学习一下时间轮算法,这里只做一个介绍)。
经过对三种淘汰策略所使用结构的介绍后,因为Caffine有多种过期策略我们来具体分析一下不同过期策略的流程:
//访问后多久过期
expireAfterAccessEntries(now);
//写后多久过期
expireAfterWriteEntries(now);
//自定义过期策略
expireVariableEntries(now);
- 访问后过期
void expireAfterAccessEntries(AccessOrderDeque<Node<K, V>> accessOrderDeque, long now) {
//获取访问后过期时间
long duration = expiresAfterAccessNanos();
for (;;) {
//循环过期掉节点
Node<K, V> node = accessOrderDeque.peekFirst();
if ((node == null) || ((now - node.getAccessTime()) < duration)
//执行过期
|| !evictEntry(node, RemovalCause.EXPIRED, now)) {
return;
}
}
}
boolean evictEntry(Node<K, V> node, RemovalCause cause, long now) {
K key = node.getKey();
@SuppressWarnings("unchecked")
V[] value = (V[]) new Object[1];
boolean[] removed = new boolean[1];
boolean[] resurrect = new boolean[1];
Object keyReference = node.getKeyReference();
//过期原因
RemovalCause[] actualCause = new RemovalCause[1];
//如果 key 对应的 value 不存在,则返回该 null,如果存在,则返回通过 remappingFunction 重新计算后的值。
data.computeIfPresent(keyReference, (k, n) -> {
if (n != node) {
return n;
}
synchronized (n) {
value[0] = n.getValue();
if ((key == null) || (value[0] == null)) {
actualCause[0] = RemovalCause.COLLECTED;
} else if (cause == RemovalCause.COLLECTED) {
resurrect[0] = true;
return n;
} else {
actualCause[0] = cause;
}
if (actualCause[0] == RemovalCause.EXPIRED) {
boolean expired = false;
if (expiresAfterAccess()) {
//如果当前时间减去访问的时间大于等于访问设置时间
expired |= ((now - n.getAccessTime()) >= expiresAfterAccessNanos());
}
if (expiresAfterWrite()) {
//如果当前时间减去写后时间大于等于设置的写时间
expired |= ((now - n.getWriteTime()) >= expiresAfterWriteNanos());
}
if (expiresVariable()) {
//节点有效期小于当前时间小于等于当前时间
expired |= (n.getVariableTime() <= now);
}
if (!expired) {
resurrect[0] = true;
return n;
}
} else if (actualCause[0] == RemovalCause.SIZE) {
int weight = node.getWeight();
if (weight == 0) {
resurrect[0] = true;
return n;
}
}
notifyEviction(key, value[0], actualCause[0]);
//处理节点
makeDead(n);
}
discardRefresh(keyReference);
removed[0] = true;
return null;
});
- 写后过期
void expireAfterWriteEntries(long now) {
if (!expiresAfterWrite()) {
return;
}
//获取写后过期时间
long duration = expiresAfterWriteNanos();
for (;;) {
//循环去过期节点
Node<K, V> node = writeOrderDeque().peekFirst();
if ((node == null) || ((now - node.getWriteTime()) < duration)
|| !evictEntry(node, RemovalCause.EXPIRED, now)) {
break;
}
}
}
- 时间轮
void expire(int index, long previousTicks, long currentTicks) {
Node<K, V>[] timerWheel = wheel[index];
int start, end;
//时间跨度比当前wheel表示的时间长,处理所有bucket
if ((currentTicks - previousTicks) >= timerWheel.length) {
end = timerWheel.length;
start = 0;
} else {//处理该wheel中时间跨度内的bucket
long mask = SPANS[index] - 1;
start = (int) (previousTicks & mask);
end = 1 + (int) (currentTicks & mask);
}
int mask = timerWheel.length - 1;
for (int i = start; i < end; i++) {
//(i & mask) start和end可能不在同一循环内。wheel是个圆,start在圆内的位置可能比end靠后
Node<K, V> sentinel = timerWheel[(i & mask)];
Node<K, V> prev = sentinel.getPreviousInVariableOrder();
Node<K, V> node = sentinel.getNextInVariableOrder();
sentinel.setPreviousInVariableOrder(sentinel);//因为这个bucket已过期,所以将数据清空
sentinel.setNextInVariableOrder(sentinel);
//node降级wheel:虽然一个node无法保留在这层wheel中了,但可能还未过期,可以放到下层的wheel中
while (node != sentinel) {
Node<K, V> next = node.getNextInVariableOrder();
node.setPreviousInVariableOrder(null);
node.setNextInVariableOrder(null);
try {
//getVariableTime这个node的过期时间。
//如果还未过期,或未能evict,寻找应该放置的位置
if (((node.getVariableTime() - nanos) > 0)
|| !cache.evictEntry(node, RemovalCause.EXPIRED, nanos)) {
schedule(node);
}
node = next;
} catch (Throwable t) {
node.setPreviousInVariableOrder(sentinel.getPreviousInVariableOrder());
node.setNextInVariableOrder(next);
sentinel.getPreviousInVariableOrder().setNextInVariableOrder(node);
sentinel.setPreviousInVariableOrder(prev);
throw t;
}
}
}
}
四、Maintenance()剩余方法
上面介绍了淘汰和过期的源码解读,这里我们对聊一下Maintenance()剩余的drainReadBuffer()和drainWriteBuffer()方法:
void maintenance(@Nullable Runnable task) {
setDrainStatusRelease(PROCESSING_TO_IDLE);
try {
//消费ReadBuffer()
drainReadBuffer();
//消费WriteBuffer()
drainWriteBuffer();
if (task != null) {
task.run();
}
//处理key引用
drainKeyReferences();
//处理值引用
drainValueReferences();
//过期节点
expireEntries();
//淘汰节点
evictEntries();
//调整内存
climb();
} finally {
if ((drainStatus() != PROCESSING_TO_IDLE) || !casDrainStatus(PROCESSING_TO_IDLE, IDLE)) {
setDrainStatusOpaque(REQUIRED);
}
}
}
- drainReadBuffer()
消费ReadBuffer主要就是为了调整访问后节点在不同区域的位置也是为了服务于淘汰和过期策略的
if (evicts()) {
//获取key
K key = node.getKey();
if (key == null) {
return;
}
//增加频率
frequencySketch().increment(key);
//看当前节点在那个区域
if (node.inWindow()) {
//更新节点在策略的队列中的位置
reorder(accessOrderWindowDeque(), node);
} else if (node.inMainProbation()) {
reorderProbation(node);
} else {
reorder(accessOrderProtectedDeque(), node);
}
setHitsInSample(hitsInSample() + 1);
//访问后过期调整节点在Window区的位置
} else if (expiresAfterAccess()) {
reorder(accessOrderWindowDeque(), node);
}
//如果自定义过期调整时间轮位置
if (expiresVariable()) {
timerWheel().reschedule(node);
}
- drainWriteBuffer()
消费ReadBuffer主要就是从写队列中拿出Task进行执行,针对于Task任务在上篇中已经展示过它的源码 了它主要用作节点频率的增加和针对不同过期策略放入不同的队列中。
void drainWriteBuffer() {
for (int i = 0; i <= WRITE_BUFFER_MAX; i++) {
//从任务队列中去除Task任务
Runnable task = writeBuffer.poll();
if (task == null) {
return;
}
//执行Task
task.run();
}
//设置状态
setDrainStatusOpaque(PROCESSING_TO_REQUIRED);
}
五、总结
到现在Caffine的策略配置和源码的一些学习就结束了,希望大家阅读的时候也能够有一定的理解,以便在后续的业务开发当中使用到Caffine能够合理的配置想要的策略,并且能够排查可能出现的问题。